正文
一、芯片设计的“换砖头”难题
要理解这场革命的深远意义,先得知道英伟达所说的“标准单元库迁移”究竟是什么。
想象一下,当一家建筑公司决定把所有盖房子的砖头,从传统红砖换成一种更轻、更坚固的新型材料时,面临的挑战:新型材料的尺寸、承重、拼接规则全都变了,需要重新设计每一块砖、每一面墙的构建方式。
芯片设计中的标准单元库迁移,就是这样一项“换砖头”的重体力活。
每当台积电或三星推出新的半导体工艺节点——比如从7nm跨越到5nm,从5nm再升级到3nm——芯片制造商必须将其包含约2500至3000个最基础的电路“砖块”(也就是标准单元),全部重新适配新工艺的物理规则。这些“砖块”包括与门、或门、非门、触发器等最基础的逻辑电路,是构成整个芯片的基石。

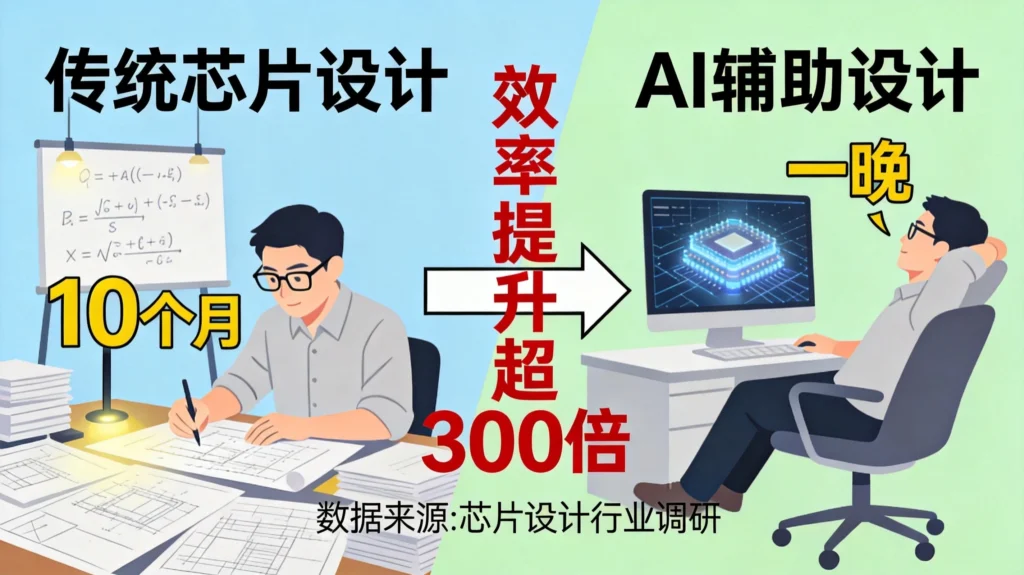
过去,这需要一支由8名资深工程师组成的精锐团队,像高级工匠一样,一个砖块一个砖块地手工适配,持续工作整整10个月。总计耗费80人月的人力成本,折算下来是惊人的时间与资金投入。
关键痛点在于:每当先进制程更新换代,这套工作就必须重来一次。对于追求每年一更旗舰显卡的英伟达而言,这意味着巨大的时间成本和人力消耗。
二、NB-Cell:AI一夜搞定芯片设计
现在,这个名为NB-Cell的AI工具,像一台超级自动化的砖块重塑机,彻底颠覆了这一切。
英伟达首席科学家比尔·达利在GTC大会上披露,基于强化学习开发的NB-Cell工具,已迭代至第二、三代,只需将需求输入系统,一块GPU在一夜之间即可完成全部迁移工作。
这个过程的效率提升是惊人的:从80人月到一块GPU的一夜,折算下来超过2400倍!
但NB-Cell的价值绝不止于“快”。更令人震撼的是,AI生成的这些新“砖块”,在三个核心指标上达到了人类水平:
- 面积(Area):更紧凑的电路布局
- 功耗(Power):更低的能耗表现
- 延迟(Delay):更短的信号传递时间
这些AI生成的单元,在关键性能指标上不仅达到了人工设计的水平,甚至在某些案例中优于人类的手工设计。这意味着,采用新工艺的门槛被彻底踏平——以前因为迁移周期太长、成本太高而犹豫的升级,现在可以毫不犹豫地推进。
这种“隔夜交付”的能力,意味着英伟达可以比竞争对手更早地跑通新工艺,从而在硬件竞赛中始终保持身位领先。
三、Prefix RL:用“打游戏”破解50年难题
如果说NB-Cell解决的是重复性劳动的效率问题,那么另一款工具Prefix RL,则展示了AI在复杂逻辑设计上的创造力——它用强化学习“打游戏”的方式,解决了困扰芯片设计界半个世纪的难题。
在芯片的算术逻辑单元(ALU)中,进位超前链(Carry Lookahead Chain)的放置,是一个自上世纪50年代就被反复研究的经典难题。它是决定CPU和GPU计算核心速度的关键路径之一,直接影响芯片的整体性能表现。
人类工程师凭借经验和直觉进行布局优化,经过几十年的摸索,形成了一套基于直觉的设计范式——但这也框定了性能的天花板。因为人类的思维模式,总是倾向于寻找“看起来合理”的解决方案。
英伟达的工程师做了一件很“暴力”的事:他们让AI像玩一款超高难度的策略游戏一样,去破解这个难题。
游戏的规则(目标)非常明确:在满足电路时序(信号不能出错)的底线前提下,把布局面积和功耗拼命往死里压缩。
AI没有经验包袱,它唯一的策略就是疯狂试错。通过强化学习,它在人类无法想象的海量设计空间里,进行数以百万、千万次的排列组合尝试。
最终,它“通关”后给出的最优解,让所有人类设计师都愣住了。
达利形容,AI生成的布局图纸“诡异至极”:走线拓扑结构完全不符合人类工程师的常规直觉,是“人类工程师永远无法想到的怪异设计”。
但更惊人的是,这套“诡异”的图纸,在测试台上跑出的硬性指标,比人类专家精心调校的最佳方案还要高出20%至30%!
这不再是“辅助设计”,而是用算法暴力,探索到了人类经验地图之外的“新大陆”。英伟达首席科学家比尔·达利对此的评价是:“这标志着AI从辅助工具向创造全新设计范式的角色转变。”
四、ChipNeMo:永不疲倦的“硅基导师”
效率工具和优化工具是“枪炮”,而英伟达还为自己打造了一个“超级大脑”——ChipNeMo。
这不是一个通用聊天机器人。它是用英伟达过去30年积累的“独家秘方”喂养出来的:包括历代GPU的底层源码(RTL代码)、架构设计白皮书、以及海量的历史缺陷报告。它经过了240亿token设计语料和13万个真实设计对话的两轮深度训练。
简单类比,这就好比一位老中医毕生的诊脉心得、药方配伍禁忌,全部被数字化、结构化,注入到了一个AI模型中。
于是,这个AI表现出了惊人的“专业素养”:
永不疲倦的导师:初级工程师遇到任何技术问题,可以直接用自然语言向它提问。它能立刻给出基于英伟达内部规范的专业解答,大幅减少了对资深工程师的重复咨询。
超级事务管家:配合Bug Nemo工具,它能自动分析、归类海量的缺陷报告,并精准分派给对应模块的负责人,把工程师从繁琐的事务性工作中解放出来。
更关键的是,ChipNeMo与NB-Cell、Prefix RL等工具并非孤立存在。它们构成了一个协同体系:ChipNeMo作为“知识引擎”和“规则手册”,确保AI设计工具在正确的框架内进行探索;而强化学习工具产出的“反直觉”成果,又可以通过ChipNeMo转化为工程师能理解的解释,形成“探索-验证-理解”的闭环。
五、从“经验手艺”到“人机协同”
当8名工程师10个月的工作被一块GPU的一夜取代时,我们不得不直面一个现实:芯片设计这门高度依赖“工匠经验”的学科,正在被AI彻底重塑。
英伟达的实践表明,这并非一场“替代人类”的革命,而是一次“范式转移”:
效率维度:NB-Cell实现了数千倍的量级压缩,扫清了工艺升级的障碍。英伟达可以比任何竞争对手更快地适配新制程。
性能维度:Prefix RL以“暴力计算”突破了人类经验的天花板,找到了人类永远想不到的更优解。
知识维度:ChipNeMo将公司数十年的核心经验资产化、民主化,重塑了人才梯队和协作模式。
工程师的角色,正从重复的“画图工”和“调试员”,加速转向更具创造性的“架构师”和“规则制定者”。
值得注意的是,英伟达并未因AI工具带来的效率提升而裁掉初级员工。比尔·达利表示,他们反而利用AI加速人才培养,让初级工程师通过ChipNeMo自主学习复杂模块的工作原理,资深工程师则专注于更高价值的创新和决策。
这或许是AI最平衡的应用之道:不是替代人,而是增强人;不是消灭岗位,而是重塑岗位价值。
六、挑战与边界:AI造芯还有多远的路?
尽管NB-Cell和Prefix RL展示了惊人的能力,但比尔·达利保持了清醒的克制。
他明确指出,完全端到端的自动化芯片设计(也就是只需说一句“给我设计一个新GPU”,AI就吐出完整图纸)距离实现还有“很长的路要走”。目前,AI扮演的角色更像是“增强设计(Augmented Design)”,而非“自主造芯”。
三大关键限制依然存在:
- 高层级架构决策仍依赖人类专家:芯片的顶层逻辑架构、模块划分、跨模块协调,仍需要人类主导。
- 创造性电路设计仍需人工主导:真正颠覆性的电路结构创新,目前仍依赖人类工程师的直觉和创造力。
- 设计验证仍是最大瓶颈:验证是整个芯片设计流程中最耗时的环节,AI只能辅助加速,无法完全闭环。
达利构想的未来,是一个“多智能体(Multi-agent)”模型:不同的专业AI系统处理不同的设计环节,就像现在的各职能团队一样协作。但接口协商、动态调整等难题,仍待攻克。
七、重新定义“摩尔定律”
当摩尔定律逼近物理极限,制程微缩的成本以指数级攀升时,芯片设计端正在成为新的“效率源泉”。
英伟达用AI在设计端挖掘出的巨大性能潜力,正在成为驱动半导体行业继续前进的新引擎。这场始于英伟达设计实验室的变革,最终将重新定义未来每一颗芯片的诞生方式。
在硅基造芯的新纪元,计算不再仅仅是芯片的目的——计算已成为芯片诞生的源头。
本文参考资料来源:英伟达GTC 2026大会演讲、中关村在线、电子工程专辑、新智元等媒体报道。