
前言
一个数字,一个转折点。
2026年5月,一组数据悄然出炉:2026年Q1,中国国产AI芯片国内市场份额首次突破50%,达到52.3%。其中,华为昇腾以37%的市占率断层第一,占国产芯片总量近70%。英伟达在华份额从巅峰的95%暴跌至42.7%。
这不是一个简单的数字变化,而是一个结构性拐点。
一、从95%到42.7%:英伟达中国滑铁卢
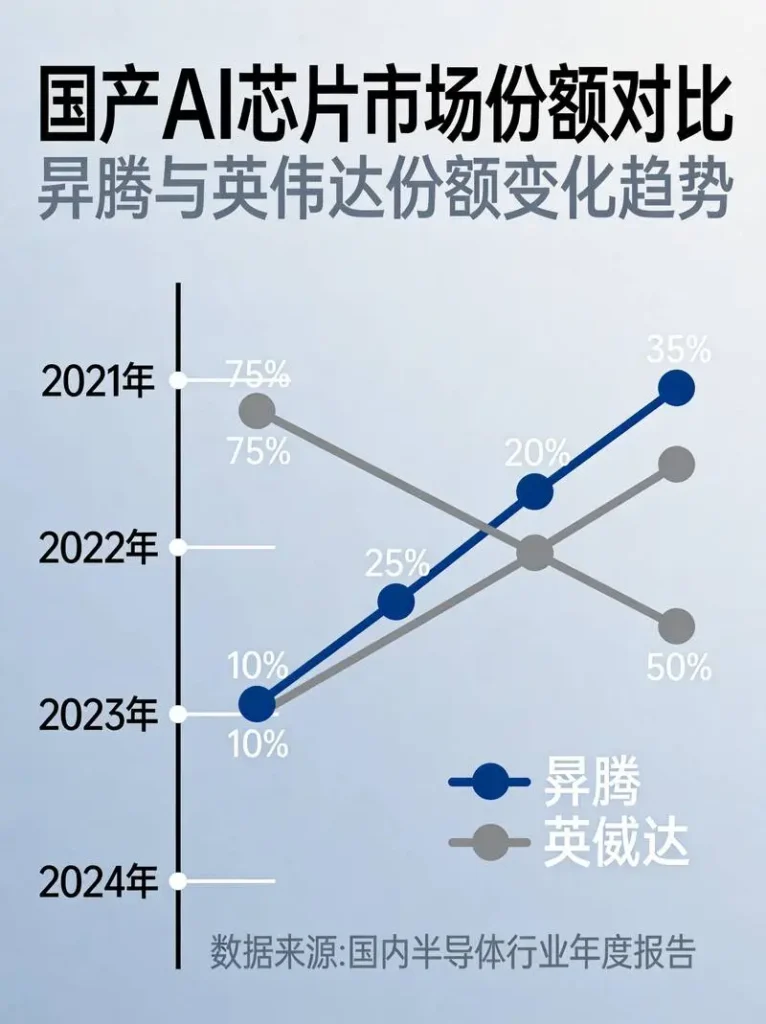
把时间拨回两年前。彼时的中国AI芯片市场,英伟达几乎是唯一的选择。无论是互联网大厂、AI创业公司还是科研机构,采购清单上的第一名永远是英伟达。数据显示,2023年英伟达在中国AI加速器市场的份额一度逼近95%。
然而,出口管制的重锤接连落下。
2022年10月,美国商务部对华实施高端芯片出口管制,A100、H100等旗舰产品无法直接对华供货。英伟达迅速推出性能削减版的A800、H800,试图绕开限制继续服务中国市场。但管制层层加码,2023年10月进一步限制互连带宽,即便阉割版也难逃封堵。到了2024年,连H20——英伟达专门为中国市场打造的“合规版”芯片——也被列入管制清单。
管制之下,英伟达的中国份额开始自由落体。
2024年底,这个数字是约70%。2025年中,跌破60%。到了2026年Q1,仅剩42.7%。 Bernstein分析师甚至预测,在当前出口管制框架下,英伟达在中国AI加速器市场的份额可能降至约8%。
这场份额雪崩的速度,超出了所有人的预期。
二、昇腾崛起:37%市占率的断层领跑
当英伟达在下坠,昇腾在起飞。
2026年Q1,华为昇腾以37%的中国市场份额断层第一。更值得注意的是,在政务、金融、能源等战略领域,国产芯片采购占比已超过70%。这些领域对供应链安全有着近乎苛刻的要求,曾经一度是英伟达最稳固的阵地,如今成了国产替代的桥头堡。
昇腾的爆发并非一夜之间。
2024年底,国产AI芯片还是“备胎”——大部分AI公司首选英伟达,国产芯片只是补充备选。2025年Q1,DeepSeek R1横空出世,证明小团队加国产算力也能打,但市场仍在观望。转折点出现在2025年下半年:昇腾910C规模化交付,多家大模型厂商启动适配。
2026年3月,昇腾950PR正式发布,这是一枚改变游戏规则的芯片。FP8算力1PFLOPS、FP4算力2PFLOPS,单卡性能相当于英伟达H20的2.87倍。这不是实验室里的纸面数据,而是可以实际部署的生产力工具。
2026年5月,DeepSeek V4全面适配昇腾950PR,完成深度定制。核心数据振奋人心:昇腾950PR上V4-Pro单卡Decode吞吐4700TPS,延迟仅20ms;推理速度提升35倍,延迟降低42%,部署成本仅为英伟达方案的三分之一。
从“能不能用”到“好不好用”再到“比进口方案更划算”,国产AI芯片用了不到两年走完了这条路上最关键的几步。
三、国产算力闭环:芯片+框架+模型的全链路整合
昇腾950PR的爆发不是孤立事件。它背后是一条正在成型的国产算力生态链。
芯片层面,华为昇腾系列已完成从910B到910C再到950PR的三代迭代,产品线覆盖训练、推理全场景。与昇腾配套的CANN(Compute Architecture for Neural Networks)异构计算架构也在持续完善,逐步降低开发者的迁移成本。
框架层面,MindSpore作为华为自研的AI框架,与昇腾芯片深度绑定。在国产替代的大背景下,MindSpore的采用率显著提升,成为仅次于PyTorch、TensorFlow的第三大AI框架。
模型层面,DeepSeek V4与昇腾950PR的全栈适配是一个里程碑事件。这不是简单的移植,而是从模型设计阶段就针对昇腾架构进行深度优化。DeepSeek创始人梁文锋将这一过程形容为“在飞行中的飞机上更换引擎”。
字节跳动2026年AI资本支出中,昇腾采购承诺超过56亿美元。阿里巴巴、腾讯等互联网巨头也在加速采购国产AI芯片。国产芯片、国产框架、国产模型——这条曾经断裂的链条正在被一节节焊接起来。
四、算力战争新战场:从“买算力”到“建算力”
国产芯片份额的突破,折射出的是一场更深层的产业变局:算力建设的主动权正在从企业手中移交给国家。
2026年5月9日,国务院常务会议的一个重磅信号震动业界——算力网首次被纳入国家“六张网”规划,与水网、新型电网、新一代通信网、城市地下管网、物流网并列。
这是什么概念?水网、电网是国家经济的血脉,算力网被放到同一层级,意味着算力从“行业资源”正式升级为“国家基础设施”。以后用算力,就像用水用电一样,是国家基础设施的基本保障。
这一战略定位的跃升,直接推动了国家级算力调度平台的建设。各省份纷纷出台算力基础设施规划,数据中心建设掀起新一轮热潮。能源成本、土地供应、网络带宽——这些曾经制约算力扩张的瓶颈,正在被系统性解决。
次日,华为与顺网联合发布“全光毫秒算网”方案,核心技术是华为OTN/50G PON全光底座实现1ms确定性时延,叠加顺网边缘算力网络覆盖近200个城市、330多个节点机房。三层时延保障:1ms(专业电竞)、5ms(政企通用)、30ms(大众娱乐),目标算力利用率提升至80%以上,用算成本降低40%-60%。
算力从中心走向边缘,从“批发”走向“零售”,从“有算力”走向“毫秒级用算力”——这才是“算力网”三个字背后的真正图景。
五、全球算力格局重构:两条路径的分叉
把目光投向全球,你会发现一个有趣的分叉正在形成。
太平洋彼岸,Anthropic正寻求以超过9000亿美元的投前估值融资至少300亿美元。资本疯狂涌入,48小时锁定份额,投资人抢额度像抢春运火车票。这家成立仅5年的公司,年化营收从90亿美元飙升至440亿美元,三个月翻了近5倍。
然而,繁荣背后是一张越织越密的算力采购巨网:Anthropic向微软承诺最高300亿美元Azure采购,向亚马逊承诺未来十年逾1000亿美元AWS采购,向谷歌锁定5吉瓦TPU算力。西方AI的商业模型本质仍是“融资→买算力→训练更强模型→获取更多客户→融更多资”的循环。
另一边,华为2026年AI芯片业务营收目标约120亿美元,同比增长超60%。昇腾950PR全年规划75万颗产能,一经出炉就被国内互联网头部大厂基本锁定,排产周期已延伸至2027年。
两条路径的本质分野已经清晰:
西方AI路径:资本驱动型。 核心资源是资本和芯片,核心变量是英伟达的供给能力。本质是“少数巨头的算力军备竞赛”。
中国AI路径:基础设施驱动型。 核心资源是自主算力和应用场景,核心变量是国产芯片的迭代速度。本质是“多数参与者的普惠基础设施建设”。
谁能走得更远,取决于AI的终局是“算力规模决定一切”,还是“场景落地决定一切”。
六、挑战与机遇:国产替代的下一程
份额首破50%是一个里程碑,但远不是终点。
技术层面,国产AI芯片在某些关键指标上仍存在差距。以HBM(高带宽内存)为例,目前国产AI芯片仍主要依赖海外供应。SK海力士、三星、美光三家厂商垄断了全球HBM市场,中国企业在HBM研发上刚刚起步。这一短板可能在下一代AI芯片的竞争中成为制约因素。
生态层面,英伟达构筑的CUDA生态壁垒依然坚固。全球数百万开发者习惯了CUDA编程接口,大量开源模型和工具链都以CUDA为默认后端。迁移到国产芯片意味着重新编译、优化和调试,这是一个漫长且成本高昂的过程。虽然华为等厂商在推动生态迁移,但生态替代的难度远超硬件替代。
商业层面,英伟达并非坐以待毙。面对出口管制,英伟达正在开发专门面向中国市场的定制芯片,试图在合规框架下重新夺回份额。黄仁勋明确表示,公司正重新审视中国市场战略。这意味着国产芯片厂商面临的竞争压力只会增加,不会减少。
但机遇同样显著。
首先,AI推理市场的爆发为国产芯片提供了新蓝海。训练阶段对算力的需求巨大,但推理阶段——模型部署后的实际运行——才是AI应用的主战场。推理芯片的技术门槛相对较低,更容易实现国产替代。目前,多家中国AI芯片厂商已在推理芯片领域形成差异化竞争力。
其次,边缘计算和端侧AI的崛起创造了新的场景需求。手机、汽车、IoT设备——这些场景对芯片的功耗、成本、集成度有特殊要求,与数据中心场景截然不同。在这些细分市场,国产芯片厂商更容易建立竞争优势。
第三,政策支持力度持续加大。从算力网纳入国家基础设施,到国产芯片采购比例要求,再到专项产业基金的支持,政策红利正在加速释放。这为国产芯片厂商提供了宝贵的发展窗口期。
结语:一场刚刚开始的算力长征
50%,一个数字,记录了中国AI芯片产业的蜕变。
曾经,我们用全球最好的芯片训练模型;曾经,“国产替代”只是一个口号;曾经,购买英伟达产品是理所当然的选择。
如今,昇腾950PR性能比肩甚至超越国际竞品,DeepSeek V4在国产算力上运行如飞,政务金融能源战略领域国产芯片成为首选。这不是弯道超车,而是一条另辟蹊径的新路。
当然,挑战依然严峻。HBM内存的短板、CUDA生态的壁垒、国际竞争的加剧——这些都是实实在在的障碍。但方向已经清晰,路径已经打通,国产算力的崛起不再是“如果”,而是“何时”的问题。
中美最前沿模型性能差距已缩小至2.7%。 Bernstein分析师预测,华为昇腾的市场份额将攀升至约50%。这些预测指向同一个未来:算力格局正在重构,而这场重构的主角之一,是中国芯片。
这是一场刚刚开始的长征。50%,只是起点。
作者:科技菌
责任编辑:Jason
发布于:2026年5月13日
本文禁止转载,如需转载,请联系编辑授权
发表回复