深夜发布,一石激起千层浪
2026年4月20日深夜,AI圈炸了。
月之暗面(Moonshot AI)悄悄丢下了一颗”深水炸弹”——正式发布并开源了旗舰模型Kimi K2.6。消息一出,开发者社区瞬间沸腾。一个号称能连续写代码13小时、同时调度300个AI”打工人”并行干活、性能直逼甚至超越GPT-5.4的模型,居然免费开放给所有人用?
这确实不是开玩笑。
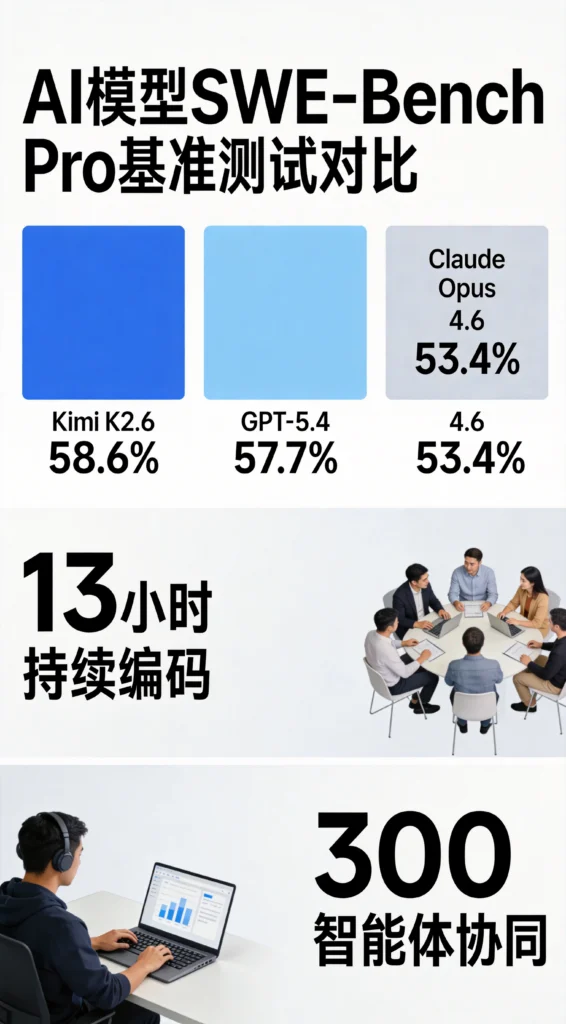
在博士级难度的完整版”终极人类考试”(Humanity’s Last Exam)、评估真实软件工程能力的SWE-Bench Pro,以及Agent深度检索基准DeepSearchQA等多项权威测试中,Kimi K2.6均取得行业领先成绩,表现持平或优于GPT-5.4、Claude Opus 4.6和Gemini 3.1 Pro等主流闭源模型。
这是开源模型首次在软件工程核心能力上全面超越闭源巨头,标志着国产AI正式进入”开源即最强”的新阶段。
三个数字,读懂Kimi K2.6的硬核实力
如果你不是程序员,可能对”大模型”的评测数据没什么概念。但这三组数字,任何人看了都会明白它的厉害:
13小时——Kimi K2.6可以不间断、全自动编写代码长达13个小时,期间无需人工干预,单次任务可编写或修改超过4000行代码。一个工程师可能要花数周才能完成的深度技术优化,K2.6用一个工作日就能跑完。
300个——该模型支持同时调度最多300个子AI智能体(Agent)并行工作,协同执行约4000个任务步骤,相当于一个AI”超级工厂”。可以把不同能力的智能体组合调度,实现搜索、深度研究、文档分析、长文创作等多种能力的并行输出。
20%——与上一代K2.5相比,Kimi K2.6在内部代码评测基准上提升了约20%,综合性能基准Claw Bench也提升了10%。
用一句话概括:这是一个可以替你”996″的AI工具,而且它不累、不抱怨、不要加班费。
13小时不间断编程:两个”不可能完成”的工程任务
光看数字可能还是抽象。让我们来看两个官方展示的实测案例。
案例一:Mac本地部署Qwen3.5-0.8B
有开发者用Kimi K2.6在Mac(M3 max)上本地部署Qwen3.5-0.8B模型,并使用小众的Zig语言实现推理优化。整个过程共调用工具4000余次,持续执行超过12小时,经历14轮迭代,最终将吞吐量从约15 tokens/s提升至约193 tokens/s——比主流工具LM Studio快20%。
这个案例的特殊之处在于Zig语言。这是一种相对小众的系统编程语言,语法复杂,生态工具链不如Python丰富。K2.6能在一个小众语言上完成完整的推理优化任务,说明它的代码能力不是”偏科生”,而是真正的全面手。
案例二:重构8年历史金融撮合引擎
另一个更震撼的案例来自对exchange-core的重构优化。这是一个有8年历史、接近性能极限的开源金融撮合引擎项目,代码量庞大,是典型的”屎山代码”场景。
K2.6独立工作了13个小时,调用工具超过1000次,制定了12套优化策略,精准修改了4000多行代码——最终,系统 中位吞吐量从0.43 MT/s跃升到1.24 MT/s,提升幅度高达185%;峰值吞吐量从1.23 MT/s飙升至2.86 MT/s,提升133%。
这种级别的性能优化,放在传统开发流程里,通常需要资深工程师花费数周甚至数月才能完成。现在,AI用一个工作日跑完了。
300个Agent集群:并行协作新范式
如果说单个模型的编程能力是K2.6的”单兵作战”能力,那Agent集群就是它的”集团军作战”能力。
K2.6的Agent集群能力在K2.5基础上做了大幅扩展:并发子Agent数量从100个扩展至300个,协同步骤从1500步扩展至4000步。这意味着更大规模的任务可以被并行处理,任务完成度和交付质量较K2.5显著提升。
Agent集群可以做什么?实测案例中,它针对全球100个半导体标的执行了5套量化策略,将麦肯锡风格的PPT逻辑沉淀为可复用技能,交付了详尽的建模表格和整套汇报演示文档。在另一个案例中,系统将一篇包含大量视觉数据的天体物理论文转化为可复用学术技能,提取论文的推理流程和可视化方法,产出了40页、7000字的研究论文,以及包含2万多条数据的结构化数据集和14张天文级图表。
这就是”集群”的意义——不是一个人在战斗,而是一群各有专长的AI智能体协同作战,最终交付的是多形态、多格式的完整产出物。
5天不停机:AI的”耐力赛”
编程能力和协作能力之外,K2.6还有一个被很多人忽视的特质:持续运行的稳定性。
月之暗面的RL基础设施团队将一个基于K2.6的Agent连续运行了5天,期间该Agent负责监控告警、故障响应和系统运维,完整覆盖从告警触发到问题解决的全流程。5天、120个小时,没有一次人工干预,没有一次系统崩溃或上下文丢失。
内部Claw Bench测试结果显示,K2.6在编程任务、即时通讯生态集成、信息检索与分析、定时任务管理及记忆调用五大维度全面领先K2.5,尤其在需要长时间自主运行且无需人工干预的工作流中优势更为显著。
这种”耐力”,对于企业级应用场景至关重要。很多AI任务不是几个小时能完成的,需要7×24小时持续运行。能稳定跑5天的AI,和跑5小时就开始”失忆”或”发疯”的AI,是完全不同的产品。
开源背后的大棋
很多人会问:这么强的模型,为什么要免费开源?
月之暗面CEO杨植麟曾有一句话:”如果模型能力达到同等水平,开源会是绝对的胜利者。”
这句话背后有清晰的商业逻辑:开源模型会吸引大量开发者在上面构建应用,形成生态;生态越繁荣,商业化空间越大;最终,开源带动的市场总量,会远超任何一家闭源公司能独自占据的份额。
Kimi K2.6并非完全”白给”。开源的是模型权重,但API调用仍然收费。这套”模型开源、服务收费”的打法,和Meta的Llama系列、DeepSeek的策略如出一辙,已经成为中国AI公司挑战国际闭源巨头的标准战法。
开源的意义不仅在于商业。站在更高的视角看,当开源模型能达到甚至超越闭源模型时,整个AI行业的技术壁垒会被打破。中小企业、研究机构、个人开发者,都能以极低的成本获取顶级AI能力。这会催生出大量闭源时代不可能出现的应用和创新。
如何使用Kimi K2.6
目前,K2.6的使用门槛已经降到极低:
- 网页版:直接访问kimi.com,对话框即可调用K2.6
- 手机APP:更新到最新版Kimi应用,切换模型即可使用
- 编程助手:Kimi Code已集成K2.6,写代码场景首选
- 开放API:在platform.moonshot.cn开发者平台调用,模型名设为kimi-k2.6
- 开源下载:Hugging Face及ModelScope均已上传模型权重,可自行本地部署
免费用户、付费订阅用户、企业API用户,全面开放,无需等待。
写在最后
Kimi K2.6的发布,是国产AI在2026年打出的又一张重量级牌。
它的意义不仅仅在于性能数字——更在于一个信号:开源大模型的天花板,正在被一次次打穿。
就在几年前,人们还普遍认为闭源模型必然比开源强。但如今,当Kimi K2.6能在真实软件工程任务中比肩GPT-5.4,这个认知正在被彻底颠覆。
当闭源巨头还在筑墙,开源的Kimi已经撕开了一道口子。这道口子的背后,是一个属于所有开发者的AI新时代。
发表回复